What Is Hadoop In Big Data?
Hadoop is an open-source software framework for storing and processing large volumes of data. It is used in Big Data because of its ability to store and process unstructured data from multiple sources. Hadoop is used to create clusters of computers that can store and process large amounts of data quickly and efficiently. It helps organizations to analyze and gain insights from large datasets, and also enables data-driven decision-making. Hadoop can be used to store and process data from sources such as social media, web logs, sensor data, and more.
Overview of Hadoop
“Hadoop is an open-source software framework for distributed storage and processing of large datasets on clusters of commodity hardware. It provides cost-effective, reliable and scalable computing solutions for big data applications. Hadoop enables enterprises to gain insights from large, varied and complex data sets, while leveraging existing IT infrastructure. It can also help reduce costs by allowing organizations to store and process data in-house, instead of relying on third-party providers. Hadoop is used by many of the world’s leading companies, including Amazon, Google, IBM, Microsoft, and Yahoo. With its powerful capabilities, Hadoop is revolutionizing the way businesses use data and handle large-scale data processing and storage.
Benefits of Hadoop
Hadoop is an open source framework that enables businesses to process large amounts of data quickly and efficiently. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. It is a powerful tool that can help businesses analyze large data sets and make informed decisions. The benefits of Hadoop include improved analytics, cost savings, faster processing, improved scalability, and improved system reliability. Hadoop provides a distributed computing platform that can store and process large amounts of data in a cost-effective and efficient manner. It can help to improve the accuracy of data analysis, which can lead to better decision-making. Additionally, it can help to reduce the time and cost associated with processing large data sets. Hadoop is an essential tool for businesses looking to make the most of their data and gain a competitive advantage.
Use Cases for Hadoop
Hadoop is an open-source software framework for distributed storage and processing of large data sets on clusters of commodity servers. It provides a way to store, process, and analyze data at massive scale, and is becoming increasingly popular for a variety of use cases. From big data analytics to machine learning to IoT, Hadoop provides an ideal platform for processing large amounts of data quickly and efficiently. In particular, Hadoop is well-suited for data-intensive applications, such as large scale analytics, processing massive data sets, and running machine learning algorithms. Additionally, Hadoop can be used for data storage and archiving, and is often employed in the creation of real-time dashboards, allowing businesses to understand and track their performance in real-time. Finally, Hadoop is also used for distributed computing, allowing businesses to run complex tasks in parallel across a cluster of computers. As the demand for data analytics and storage grows, Hadoop is becoming an increasingly popular choice for businesses of all sizes.
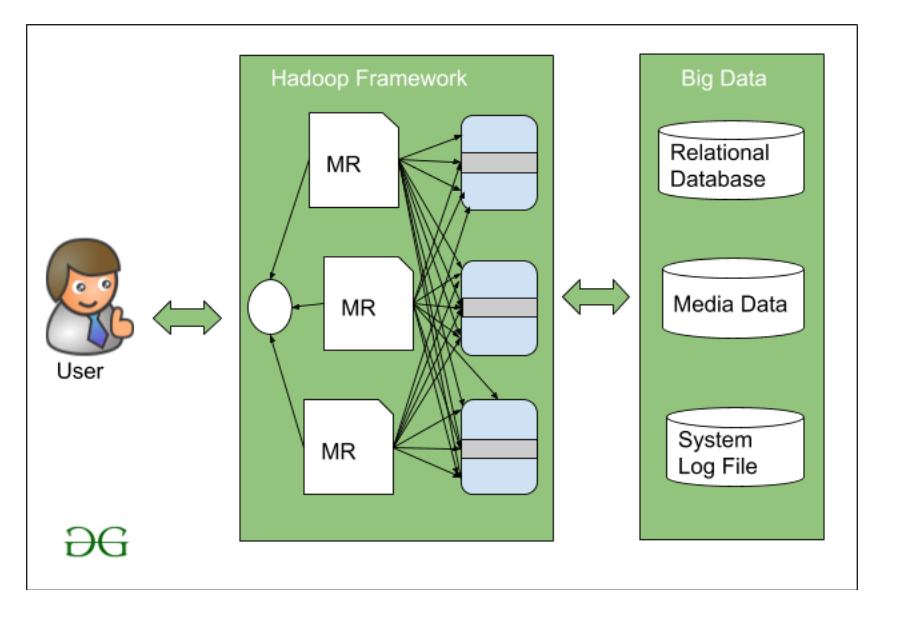
Components of Hadoop
Hadoop is a powerful distributed computing platform that enables businesses to store and process large datasets. It is made up of four components: the HDQRS (Hadoop Distributed File System), YARN (Yet Another Resource Negotiator), Map Reduce, and Common. The HDQRS is the storage layer of Hadoop, allowing businesses to store large amounts of data in a distributed manner. YARN is the resource management layer, allowing for efficient resource management across different applications. Map Reduce is the processing layer of Hadoop, allowing businesses to efficiently process their large data sets. Lastly, Common is the set of libraries and utilities that support the other components of Hadoop. Taken together, these components allow businesses to store, manage and process large data sets quickly and efficiently.
Challenges of Using Hadoop
Hadoop is an open-source software framework used for distributed storage and processing of large datasets. Although Hadoop is becoming increasingly popular, its use is not without its challenges. One of the biggest challenges of Hadoop is its complexity. The architecture of the system, its components and the different ways it can be used are all quite complex. Additionally, Hadoop can be difficult to set up and maintain due to its distributed nature. Other challenges with Hadoop include scalability and performance. To get the most out of Hadoop, users need to have a good understanding of the platform and its various components. As a result, it can be difficult to find experienced Hadoop professionals. Lastly, there are security risks associated with Hadoop, as it can be used to store sensitive data. Despite these challenges, Hadoop is still a popular choice for distributed storage and processing of large datasets.
FAQs About the What Is Hadoop In Big Data?
1. What is the purpose of Hadoop in Big Data?
Answer: Hadoop is an open-source software framework designed to store and process large volumes of data. It is used to store large datasets and process them in a distributed fashion, allowing for better scalability and performance.
2. What are the components of Hadoop?
Answer: The main components of Hadoop include the Hadoop Distributed File System (HDQRS), Map Reduce, and YARN. HDQRS is a distributed file system that stores data across multiple nodes in a Hadoop cluster. Map Reduce is a programming model used to process and analyze large datasets stored in HDQRS. YARN is a resource management platform that allows multiple data processing engines to access data stored in HDQRS.
3. How is Hadoop used in Big Data?
Answer: Hadoop is used to store, process, and analyze Big Data. It enables organizations to store large volumes of data across multiple nodes and process it in a distributed fashion. Hadoop also provides access to a wide range of data processing engines that enable organizations to analyze large datasets and get insights from them.
Conclusion
Hadoop is an open source big data platform that enables distributed storage and processing of large datasets across clusters of commodity servers. It provides an efficient and effective method of processing and storing massive amounts of data in a cost-effective way. Hadoop has become an essential tool for enterprises to store, analyze, and process large and complex datasets. It is an important component of big data and is used in a variety of industries for various applications.